Overview: Paradigm Comparison
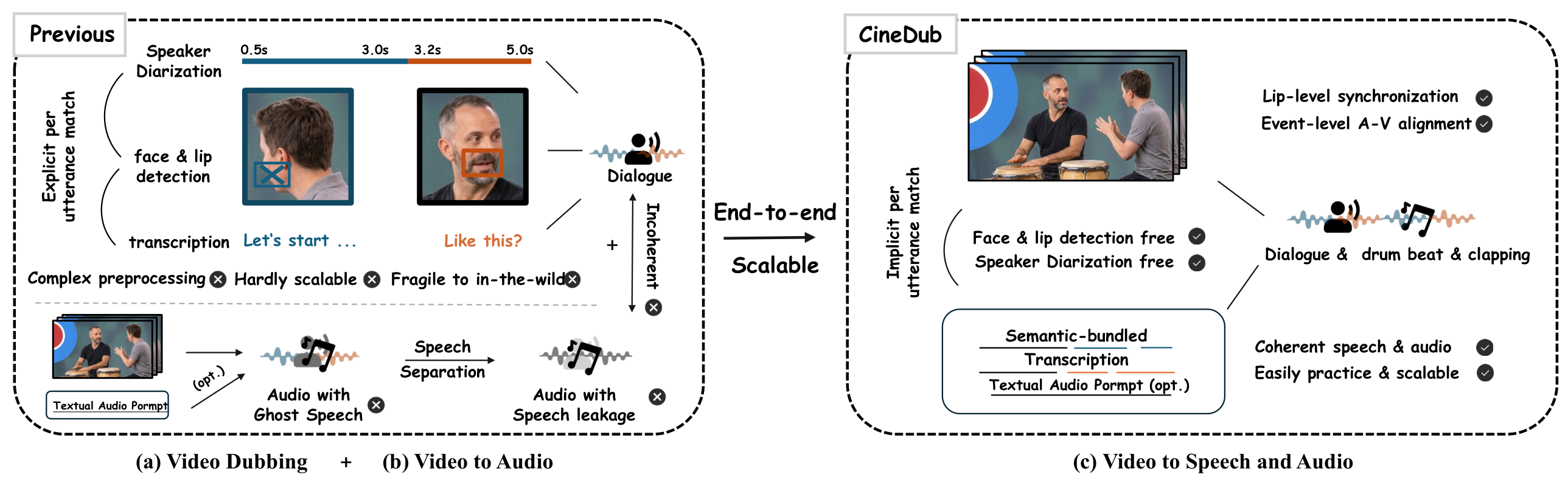
(a) Existing video dubbing methods rely on complex preprocessing — speaker diarization, face & lip detection, and forced alignment — limiting scalability and practicality in the wild. (b) Generating accompanying sound effects requires a separate V2A model, which inevitably introduces ghost speech artifacts — spurious speech-like sounds from the V2A model that corrupt the final mix — and acoustic incoherence between independently generated speech and audio. (c) CineDub jointly generates multi-speaker dialogue with coherent sound effects through a single unified end-to-end model, requiring only an uncropped video and an MLLM-generated semantic-bundled transcription.
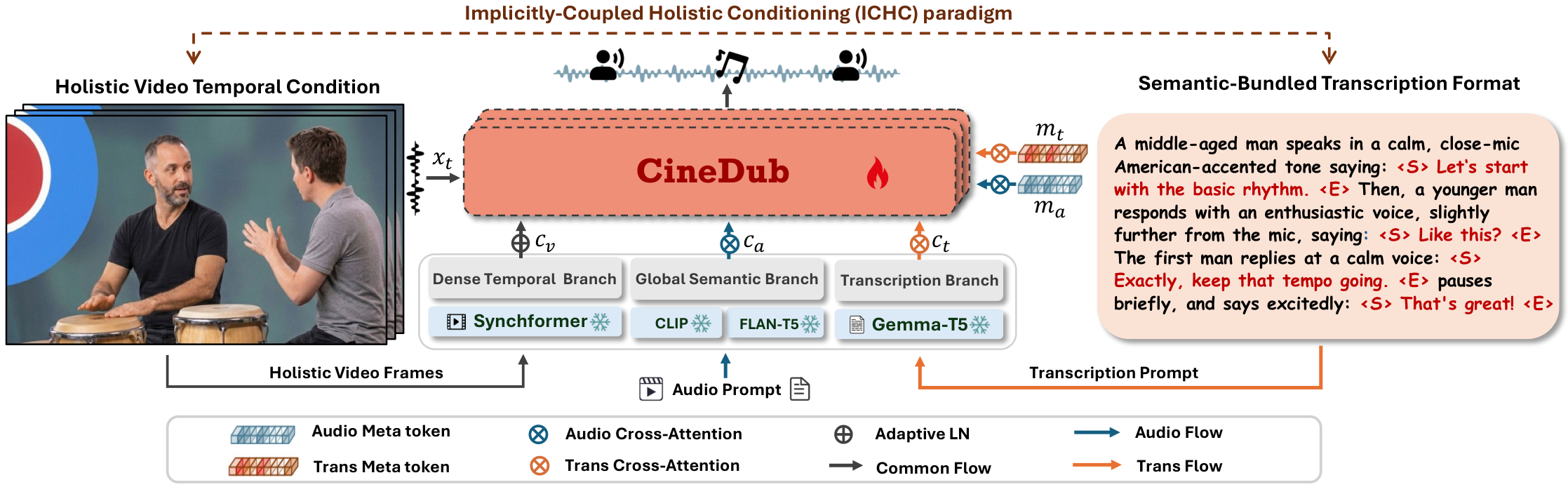
The ICHC paradigm of CineDub. The holistic visual condition extracted by SynchFormer encodes both event-level audio-visual correspondences and fine-grained lip-sync alignment. The semantic-bundled transcription provides per-segment speaker-utterance grounding cues, implicitly coupling with visual features via multi-conditional training to resolve speaker ambiguity. Speech and audio prompts are routed through decoupled textual branches to prevent cross-prompt interference, with learnable meta-tokens replacing inactive branches during single-task inference to achieve expert-mode performance.